BLEU
一种机器翻译评价方法,虽然是为机器翻译提出,但后来也广泛用于NLP其他领域。
原理
语言的评价是很困难的,这不是简单的分类,涉及句子的流畅性、充分性和准确性等。然而人工去做这件事很显然是不现实的,还有就是个人会掺杂一些主观因素。
BLEU:bilingual evaluation understudy
N_Grem
指文本中连续出现的n个语词。n元语法模型是基于(n-1)阶马尔可夫链的一种概率语言模型,通过n个语词出现的概率来推断语句的结构。
- 例子
1 | 原文: 猫坐在垫子上 |
- 1_grem
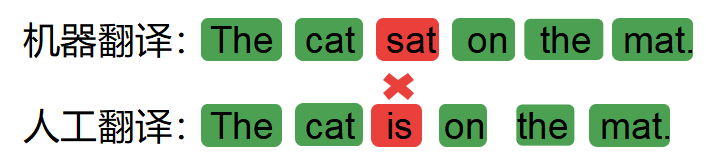
匹配度是5/6
- 2_grem
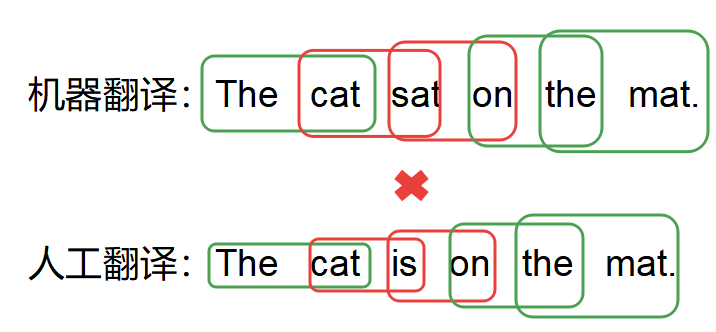
匹配度是3/5
- 3_grem
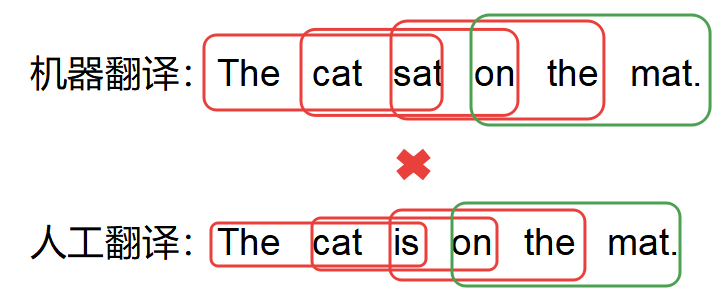
匹配度是1/4
- 4_grem

匹配度是0
1_grem表示有多少个独立的词被翻译出来了,n>=2_grem反应翻译的流畅程度。
改进的N_grem
如果是这种情况

计算1_grem是6/6.很明显是不合理的,所以取分子部分为机器翻译和参考翻译词出现次数的最小值。
Count_clip = min(Count,Max_Ref_Count)
各阶N_grem计算公式:
$p_n=\frac{\sum_{C\in{Candidates}}\sum _ { n - g r a m \in C }Count_ { c l i p } ( n - g r a m )}{\sum_{C ^ { \prime } \in {Candidates}}\sum _ { n - g r a m ^{\prime} \in C ^{\prime}}Count_ { c l i p } ( n - g r a m ^ {\prime})}$
分子部分表示N_grem翻译和参考译文中的出现次数
以上边的句子为例,计算到4_grem
分子 = 5/6 + 3/5 + 1/4 = 202/120
分母表示N_grem在翻译译文中的出现次数:
分母 = 5/6 + 5/5 + 4/4 + 3/3 = 460/120
pn = 202/460
当句子较短时
| Candidate | the | cat | |||||
| Reference1 | the | cat | is | on | the | mat | |
| Reference2 | there | is | a | cat | on | the | mat |
很明显,分母(等于2)部分会很小,导致pn很大,所以要加入短句惩罚项。
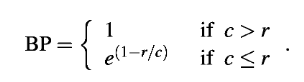
当翻译句长大于参考句长时,BP为1,当小于时,BP为上公式计算得出
为了使n_grem权重平均,使用了几何加权平均
最后BLEU公式如下
$\mathrm { BLEU } = \mathrm { BP } \cdot \exp \left( \sum _ { n = 1 } ^ { N } w _ { n } \log p _ { n } \right)$
使用对数形式使公式更加简洁
$\log \mathrm { BLEU } = \min \left( 1 - \frac { r } { c } , 0 \right) + \sum _ { n = 1 } ^ { N } w _ { n } \log p _ { n }$
特点
优点
- 它的计算速度快,容易,特别是与人工翻译速率模型输出相比。
- 它无处不在。这使您可以轻松地将模型与同一任务的基准进行比较。
- 不幸的是,这种非常便利导致人们过度使用它,即使对于那些不是最佳度量选择的任务也是如此。
缺点
- 它没有考虑句子意义
- 它不直接考虑句子结构
- 它不能很好地处理形态丰富的语言
- 它不能很好地映射到人类的判断
BLEU在一定程度上解决了NLP的评价问题,但是还存在诸多缺陷,下面是大佬的一篇文章
https://medium.com/@rtatman/evaluating-text-output-in-nlp-bleu-at-your-own-risk-e8609665a213